

The Requirement
Our customer wanted an AI-driven system to accurately identify and classify the language accordingly. This would facilitate the automated captioning service for hard-of-hearing consumers. The API-based solution had to be scalable across their entire range of different products.
The Challenges
The challenges were:
- Lack of spoken language detection process/system in place. Their transcription services transcribed every language, while the need was limited to only English captioning. So, it was high overhead in terms of cost and service.
- Due to the lack of notification, the users were unable to comprehend when the speaker was silent.
- Scalability was a challenge due to limited capability in handling call throughput.
The Solution
We designed a custom AI-powered platform that was sandwiched between the user and the transcription system using APIs. The platform could now:
- Accurately distinguish between English and other languages
- Handle a higher throughput of 300-400 requests per second
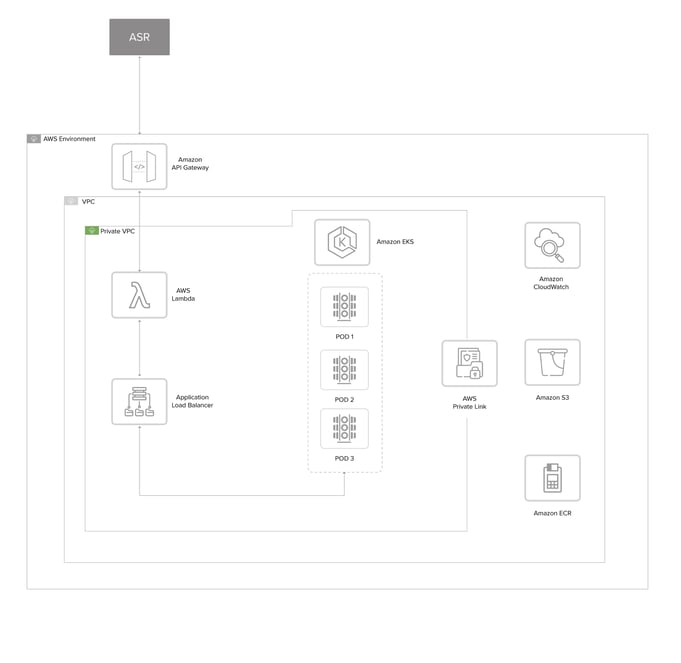
Our Approach
We designed & implemented a custom Deep Neural Network (DNN) for efficient spoken language identification. This platform was integrated into the system utilizing APIs and deployed on a cost-efficient, multi-region, active-active & scalable cloud architecture that could handle traffic at peak times.
To achieve this high throughput, we modified the DNN architecture to adapt model quantization while training the AI model. With this technique, we reduced the model size to around 61 MB, from the original size of 1.5 GB. We used EKS to deploy the model as a part of the backend, which is configured to scale based on the traffic.
Training the AI model
We designed the end-to-end pipeline from data pre-processing to training the model, CI/CD pipeline to deploying the updated model. We began with building the data set on which the training could begin. We designed and implemented a custom feature extractor, via which we added additional noise, manipulated speed, pitch and noise deformer, normalized the frequency, transcoded the audio chunks, and much more. The transcoded audio data was then passed through another pipeline of aggregated feature extraction, including filter banks and MFCC.
Tech Stack
.jpg?width=355&name=Clear%20Caption%20(2).jpg)
Business Benefit
-
- Improved customer experience by displaying a notification on detecting non-English language or silence at the speaker end.
- 25% reduction in transcription costs by not passing non-English conversations to the Transcription service
- Enhanced product efficiency with lower latency and serve requests at 900 ms.
- Enhanced product performance to handle 1200+ concurrent calls at any given time.