Light

As the name suggests, an enterprise IT system tends to have enterprise-level intricacies and cross-dependencies. Due to the high adoption level of cloud and other digital technologies, the very idea of restricting computing within the confines of a room or building is a long-forgotten concept.
The tech stack needs of different teams within an organization, as well as the digital demands of customers, cannot be holistically benchmarked. As a result, decentralization is gaining traction, slowly and steadily. Decentralization enables organizations to be nimbler and more transformative in response to customer demands.
However, it also makes it harder for centralized functionalities and decentralized teams to harmoniously work together and achieve or maintain high levels of operational efficiency and IT service quality.
This is when Site Reliability Engineering (SRE) comes into play. SRE focuses on the continuous health and performance of applications and services, used by both employees and customers. SRE engineers, equipped with code and automation expertise, bridge the gap between operations and development and get rid of manual, monotonous tasks that serve as a barrier to achieving optimal service and system health levels.
The difference that SRE makes is strikingly evident. According to a ServiceNow report, 42% of IT organizations with a well-entrenched SRE practice reported outstanding quality of IT service, compared to the average of 30%. Also, SRE-driven organizations reported that 77% of IT tasks and processes were already automated, compared to the average of 58%.
What is SRE?
SRE is the application of software engineering methodologies and procedures to resolve or manage reliability issues with team operations and site infrastructure. It has also evolved from being a purely technical practice to having a larger impact on organizations and the achievement of their business goals.
Ben Treynor Sloss originated the name and practice of SRE at Google. Being a software engineer himself, he did what he knew best; he applied software engineering principles and practices to the operations side of things. The rationale behind such an approach was that product development and operations teams were not working in tandem and therefore had different goals.
The product development team focused on introducing new features and figuring out how these features were adopted by users. On the other hand, the operations team focused on making sure that services were humming along nicely. Each team had their own working style, which created a disconnect in terms of accomplishing business goals.
To bridge this gap, Ben made sure that his engineers spent 50% of their time on operational tasks to have a clear understanding of software in a production environment. From humble beginnings, the SRE team at Google now has 1000+ engineers and SRE has been widely adopted across the software industry.

What Role Does a SRE Engineer Play?
A SRE engineer is a uniquely positioned role in the world of technology. They are either software engineers with some background in operations or system admins/IT operations executives with software development skills.
A SRE engineer oversees availability, latency, performance, efficiency, change management, monitoring, emergency response and capacity planning of services. In simple terms, a SRE engineer keeps a keen eye on services in production, stabilizes them when needed and preserves sustainable performance and availability thresholds.
SRE engineers prescribe an exact numerical value, which is set as the system availability objective. This objective is termed as a Service-Level Objective (SLO). SLO is indicative of whether a system can perform its intended function. A Service-level Agreement (SLA) typically is an agreement that assures attainment of a specified SLO level over a period of time. Non-adherence can lead to some sort of penalty. A Service-Level Indicator (SLI) is a measurement of the availability of a system service. So, when assessing the SLO of a system, say over a period of 7 days, SRE engineers look at the SLI to obtain the service availability percentage.
It seems like a lot to do and it is; however, another key objective of a SRE engineer is to automate wherever possible. This approach is the result of a host of software technologies, platforms, cloud computing options and devices, which generate tons of data.
Such a massive proliferation of technologies is the direct outcome of digital transformation. It is highly scalable and practical to manage large systems, consisting of thousands and thousands of machines, through code and automation. Typically, an SRE performs the following activities:
- Responding to system incidents or system outages
- Post-incident analysis and related documentation
- Taking part in on-call rotations
- Developing applications or IT capabilities
- Writing business processes, business rules or SRE best practices
- Usage/cost allocation audits
- Starting new hosts and instances
- Improving skills and knowledge through experimentation and training
- Releasing roadmap planning
- Conducting chaos-engineering activities
- Providing training on third-party platform competencies
- Load testing and other capacity management tasks
SRE & DevOps Work Hand in Glove Together
DevOps, as a practice, came into being well before SRE. Once SRE was created, conflicts arose as to which methodology to implement. The truth is that SRE and DevOps are extremely complementary practices.
DevOps defines the ‘Why’ and SRE defines the ‘How.’ For example, both practices accept failures as an unavoidable manifestation. DevOps looks at managing runtime errors and derives learning from them, whereas SRE tries to fulfill error management via Service Level Commitments (SLC), which in turn ensures that all failures are managed. According to the Google State of DevOps 2021 report, 52% of respondents (DevOps teams) reported the use of SRE practices.
The primary objective of both SRE and DevOps is to bridge the gap between development and operations teams to deliver products and services at a faster rate. Rapid application development life cycles, higher service quality and reliability levels and lesser IT time and effort per developed application are some of the benefits that can be accomplished by both the SRE and DevOPs functions.
The key differentiator that SRE brings to the table is the ability of SRE engineers to remove communication and workflow roadblocks, as they also possess operations experience. They can aid DevOps teams when their developers are swamped with operations tasks and they need a software engineer with highly-specialized operations skills.
The Path to SRE Excellence
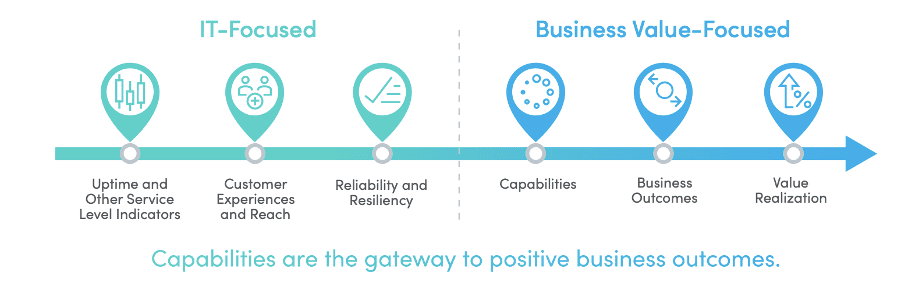
Usually, SREs focus on operational-level discussions and ensure that services are always reliable. They also place great emphasis on how swiftly incidents are resolved, the exact time taken between failures and how quickly the root cause analysis of the incident can be performed.
However, the missing link here is that SREs need to further align their goals with tangible business outcomes and the process of deriving customer value.
So, what is the next step? Companies could try to nudge their already overworked IT operations/services team to adopt SRE as a function. Or they can engage a SRE partner who can completely take over the SRE function and scale it for the future.
As digital experience experts, SRE is an organic extension of what we do at Material. Through our consultative model, we first perform an exhaustive analysis of our customers’ existing IT systems, determine what comes under the purview of SRE, zero in on the how and why and then work with you to implement those solutions.
Interested learning how Material’s SRE experts can help optimize your enterprise IT system?

